Access SQL. Основные понятия, лексика и синтаксис
Для извлечения данных из базы данных используется язык SQL. SQL - это язык программирования, который очень напоминает английский, но предназначен для программ управления базами данных. SQL используется в каждом запросе в Access.
Понимание принципов работы SQL помогает создавать более точные запросы и упрощает исправление запросов, которые возвращают неправильные результаты.
Это статья из цикла статей о языке SQL для Access. В ней описаны основы использования SQL для выборки данных и приведены примеры синтаксиса SQL.
В этой статье
Что такое SQL?
SQL - это язык программирования, предназначенный для работы с наборами фактов и отношениями между ними. В программах управления реляционными базами данных, таких как Microsoft Office Access, язык SQL используется для работы с данными. В отличие от многих языков программирования, SQL удобочитаем и понятен даже новичкам. Как и многие языки программирования, SQL является международным стандартом, признанным такими комитетами по стандартизации, как ISO и ANSI .
На языке SQL описываются наборы данных, помогающие получать ответы на вопросы. При использовании SQL необходимо применять правильный синтаксис. Синтаксис - это набор правил, позволяющих правильно сочетать элементы языка. Синтаксис SQL основан на синтаксисе английского языка и имеет много общих элементов с синтаксисом языка Visual Basic для приложений (VBA).
Например, простая инструкция SQL, извлекающая список фамилий контактов с именем Mary, может выглядеть следующим образом:
SELECT Last_Name
FROM Contacts
WHERE First_Name = "Mary";
Примечание: Язык SQL используется не только для выполнения операций над данными, но еще и для создания и изменения структуры объектов базы данных, например таблиц. Та часть SQL, которая используется для создания и изменения объектов базы данных, называется языком описания данных DDL. Язык DDL не рассматривается в этой статье. Дополнительные сведения см. в статье Создание и изменение таблиц или индексов с помощью запроса определения данных .
Инструкции SELECT
Инструкция SELECT служит для описания набора данных на языке SQL. Она содержит полное описание набора данных, которые необходимо получить из базы данных, включая следующее:
таблицы, в которых содержатся данные;
связи между данными из разных источников;
поля или вычисления, на основе которых отбираются данные;
условия отбора, которым должны соответствовать данные, включаемые в результат запроса;
необходимость и способ сортировки.
Предложения SQL
Инструкция SQL состоит из нескольких частей, называемых предложениями. Каждое предложение в инструкции SQL имеет свое назначение. Некоторые предложения являются обязательными. В приведенной ниже таблице указаны предложения SQL, используемые чаще всего.
Предложение SQL | Описание | Обязательное |
|---|---|---|
|
Определяет поля, которые содержат нужные данные. |
||
|
Определяет таблицы, которые содержат поля, указанные в предложении SELECT. |
||
|
Определяет условия отбора полей, которым должны соответствовать все записи, включаемые в результаты. |
||
|
Определяет порядок сортировки результатов. |
||
|
В инструкции SQL, которая содержит статистические функции, определяет поля, для которых в предложении SELECT не вычисляется сводное значение. |
Только при наличии таких полей |
|
|
В инструкции SQL, которая содержит статистические функции, определяет условия, применяемые к полям, для которых в предложении SELECT вычисляется сводное значение. |
Термины SQL
Каждое предложение SQL состоит из терминов, которые можно сравнить с частями речи. В приведенной ниже таблице указаны типы терминов SQL.
Термин SQL | Сопоставимая часть речи | Определение | Пример |
|---|---|---|---|
|
идентификатор |
существительное |
Имя, используемое для идентификации объекта базы данных, например имя поля. |
Клиенты.[НомерТелефона] |
|
оператор |
глагол или наречие |
Ключевое слово, которое представляет действие или изменяет его. |
|
|
константа |
существительное |
Значение, которое не изменяется, например число или NULL. |
|
|
выражение |
прилагательное |
Сочетание идентификаторов, операторов, констант и функций, предназначенное для вычисления одного значения. |
>= Товары.[Цена] |
Основные предложения SQL: SELECT, FROM и WHERE
Общий формат инструкций SQL:
SELECT field_1
FROM table_1
WHERE criterion_1
;
Примечания:
Access не учитывает разрывы строк в инструкции SQL. Несмотря на это, каждое предложение рекомендуется начинать с новой строки, чтобы инструкцию SQL было удобно читать как тому, кто ее написал, так и всем остальным.
Каждая инструкция SELECT заканчивается точкой с запятой (;). Точка с запятой может стоять как в конце последнего предложения, так и на отдельной строке в конце инструкции SQL.
Пример в Access
В приведенном ниже примере показано, как в Access может выглядеть инструкция SQL для простого запроса на выборку.
1. Предложение SELECT
2. Предложение FROM
3. Предложение WHERE
Разберем пример по предложениям, чтобы понять, как работает синтаксис SQL.
Предложение SELECT
SELECT , Company
Это предложение SELECT. Оно содержит оператор (SELECT), за которым следуют два идентификатора ("[Адрес электронной почты]" и "Компания").
Если идентификатор содержит пробелы или специальные знаки (например, "Адрес электронной почты"), он должен быть заключен в прямоугольные скобки.
В предложении SELECT не нужно указывать таблицы, в которых содержатся поля, и нельзя задать условия отбора, которым должны соответствовать данные, включаемые в результаты.
В инструкции SELECT предложение SELECT всегда стоит перед предложением FROM.
Предложение FROM
FROM Contacts
Это предложение FROM. Оно содержит оператор (FROM), за которым следует идентификатор (Контакты).
В предложении FROM не указываются поля для выборки.
Предложение WHERE
WHERE City="Seattle"
Это предложение WHERE. Оно содержит оператор (WHERE), за которым следует выражение (Город="Ростов").
С помощью предложений SELECT, FROM и WHERE можно выполнять множество действий. Дополнительные сведения об использовании этих предложений см. в следующих статьях:
Сортировка результатов: ORDER BY
Как и в Microsoft Excel, в Access можно сортировать результаты запроса в таблице. Используя предложение ORDER BY, вы также можете указать способ сортировки результатов при выполнении запроса. Если используется предложение ORDER BY, оно должно находиться в конце инструкции SQL.
Предложение ORDER BY содержит список полей, для которых нужно выполнить сортировку, в том же порядке, в котором будут применена сортировка.
Предположим, например, что результаты сначала нужно отсортировать по полю "Компания" в порядке убывания, а затем, если присутствуют записи с одинаковым значением поля "Компания", - отсортировать их по полю "Адрес электронной почты" в порядке возрастания. Предложение ORDER BY будет выглядеть следующим образом:
ORDER BY Company DESC,
Примечание: По умолчанию Access сортирует значения по возрастанию (от А до Я, от наименьшего к наибольшему). Чтобы вместо этого выполнить сортировку значений по убыванию, необходимо указать ключевое слово DESC.
Дополнительные сведения о предложении ORDER BY см. в статье Предложение ORDER BY .
Работа со сводными данными: предложения GROUP BY и HAVING
Иногда возникает необходимость работы со сводными данными, такими как итоговые продажи за месяц или самые дорогие товары на складе. Для этого в предложении SELECT к полю применяется агрегатная функция. Например, если в результате выполнения запроса нужно получить количество адресов электронной почты каждой компании, предложение SELECT может выглядеть следующим образом:
Возможность использования той или иной агрегатной функции зависит от типа данных в поле и нужного выражения. Дополнительные сведения о доступных агрегатных функциях см. в статье Статистические функции SQL .
Задание полей, которые не используются в агрегатной функции: предложение GROUP BY
При использовании агрегатных функций обычно необходимо создать предложение GROUP BY. В предложении GROUP BY указываются все поля, к которым не применяется агрегатная функция. Если агрегатные функции применяются ко всем полям в запросе, предложение GROUP BY создавать не нужно.
Предложение GROUP BY должно следовать сразу же за предложением WHERE или FROM, если предложение WHERE отсутствует. В предложении GROUP BY поля указываются в том же порядке, что и в предложении SELECT.
Продолжим предыдущий пример. Пусть в предложении SELECT агрегатная функция применяется только к полю [Адрес электронной почты], тогда предложение GROUP BY будет выглядеть следующим образом:
GROUP BY Company
Дополнительные сведения о предложении GROUP BY см. в статье Предложение GROUP BY .
Ограничение агрегированных значений с помощью условий группировки: предложение HAVING
Если необходимо указать условия для ограничения результатов, но поле, к которому их требуется применить, используется в агрегированной функции, предложение WHERE использовать нельзя. Вместо него следует использовать предложение HAVING. Предложение HAVING работает так же, как и WHERE, но используется для агрегированных данных.
Предположим, например, что к первому полю в предложении SELECT применяется функция AVG (которая вычисляет среднее значение):
SELECT COUNT(), Company
Если вы хотите ограничить результаты запроса на основе значения функции COUNT, к этому полю нельзя применить условие отбора в предложении WHERE. Вместо него условие следует поместить в предложение HAVING. Например, если нужно, чтобы запрос возвращал строки только в том случае, если у компании есть несколько адресов электронной почты, можно использовать следующее предложение HAVING:
HAVING COUNT()>1
Примечание: Запрос может включать и предложение WHERE, и предложение HAVING, при этом условия отбора для полей, которые не используются в статистических функциях, указываются в предложении WHERE, а условия для полей, которые используются в статистических функциях, - в предложении HAVING.
Дополнительные сведения о предложении HAVING см. в статье Предложение HAVING .
Объединение результатов запроса: оператор UNION
Оператор UNION используется для одновременного просмотра всех данных, возвращаемых несколькими сходными запросами на выборку, в виде объединенного набора.
Оператор UNION позволяет объединить две инструкции SELECT в одну. Объединяемые инструкции SELECT должны иметь одинаковое число и порядок выходных полей с такими же или совместимыми типами данных. При выполнении запроса данные из каждого набора соответствующих полей объединяются в одно выходное поле, поэтому выходные данные запроса имеют столько же полей, сколько и каждая инструкция SELECT по отдельности.
Примечание: В запросах на объединение числовой и текстовый типы данных являются совместимыми.
Используя оператор UNION, можно указать, должны ли в результаты запроса включаться повторяющиеся строки, если таковые имеются. Для этого следует использовать ключевое слово ALL.
Запрос на объединение двух инструкций SELECT имеет следующий базовый синтаксис:
SELECT field_1
FROM table_1
UNION
SELECT field_a
FROM table_a
;
Предположим, например, что имеется две таблицы, которые называются "Товары" и "Услуги". Обе таблицы содержат поля с названием товара или услуги, ценой и сведениями о гарантии, а также поле, в котором указывается эксклюзивность предлагаемого товара или услуги. Несмотря на то, что в таблицах "Продукты" и "Услуги" предусмотрены разные типы гарантий, основная информация одна и та же (предоставляется ли на отдельные продукты или услуги гарантия качества). Для объединения четырех полей из двух таблиц можно использовать следующий запрос на объединение:
SELECT name, price, warranty_available, exclusive_offer
FROM Products
UNION ALL
SELECT name, price, guarantee_available, exclusive_offer
FROM Services
;
Дополнительные сведения об объединении инструкций SELECT с помощью оператора UNION см. в статье
На уроке будет рассмотрен язык запросов sql: основы синтаксиса языка sql, работа в phpMyAdmin и сервисе для онлайн проверки sql запросов
База данных - централизованное хранилище данных, обеспечивающее хранение, доступ, первичную обработку и поиск информации.
Базы данных разделяются на:
- Иерархические
- Сетевые
- Реляционные
- Объектно-ориентированные
SQL (Structured Query Language) — представляет из себя структурированный язык запросов (перевод с английского). Язык ориентирован на работу с реляционными (табличными) базами данных. Язык прост и, по сути, состоит из команд (интерпретируемый), посредством которых можно работать с большими массивами данных (базами данных), удаляя, добавляя, изменяя информацию в них и осуществляя удобный поиск.
Для работы с SQL кодом необходима система управления базами данных (СУБД), которая предоставляет функционал для работы с базами данных.
Система управления базами данных (СУБД) - совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования БД многими пользователями.
Обычно, для обучения используется СУБД Microsoft Access , но мы будем использовать более распространенную в веб сфере систему — . Для удобства будет использовать веб-интерфейс или онлайн сервис для построения sql запросов , принцип работы с которыми описан ниже.
Важно: При работе с реляционными или табличными базами данных строки таблицы будем называть записями , а столбцы — полями .
Каждый столбец должен иметь свой тип данных, т.е. должен быть предназначен для внесения данных определенного типа. описаны в одном из уроков данного курса.
Составляющие языка SQL
Язык SQL состоит из следующих составных частей:
- язык манипулирования данными (Data Manipulation Language, DML);
- язык определения данных (Data Definition Language, DDL);
- язык управления данными (Data Control Language, DCL).
1.
Язык манипулирования данными состоит из 4 главных команд:
- выборка данных из БД —
- вставка данных в таблицу БД —
- обновление (изменение) данных в таблицах БД —
- удаление данных из БД —
Язык определения данных используется для создания и изменения структуры базы данных и ее составных частей — таблиц, индексов, представлений (виртуальных таблиц), а также триггеров и сохраненных процедур.
Мы будем рассматривать лишь несколько из основных команд языка . Ими являются:
- создание базы данных — CREATE DATABASE
- создание таблицы — CREATE TABLE
- изменение таблицы (структуры) — ALTER TABLE
- удаление таблицы — DROP TABLE
Язык управления данными используется для управления правами доступа к данным и выполнением процедур в многопользовательской среде.
Как сделать sql запрос в phpmyadmin
- Запустить ярлык start denwer .
- В адресной строке браузера набрать http://localhost/tools/phpmyadmin .
- В левой части окна выбрать интересующую базу данных или создать ее (если еще не создана). Создание базы данных в phpmyadmin рассмотрено .
- Если известна таблица, с которой будет работать запрос — в левой части окна выбрать эту таблицу.
- Выбрать вкладку SQL и начать вводить запрос.
Создание базы данных в phpmyadmin
Для начала необходимо выполнить первые два пункта из .
Затем:
- в открывшемся веб-интерфейсе выбрать вкладку Базы данных ;
- в поле Создать базу данных ввести название базы;
- щелкнуть по кнопке Создать ;
- теперь для продолжения работы в phpMyAdmin в созданной базе данных можно перейти к .

Работа в сервисе sql fiddle
Онлайн проверка sql запросов возможна при помощи сервиса .
Самый простой способ организации работы состоит из следующих этапов:

Еще пример: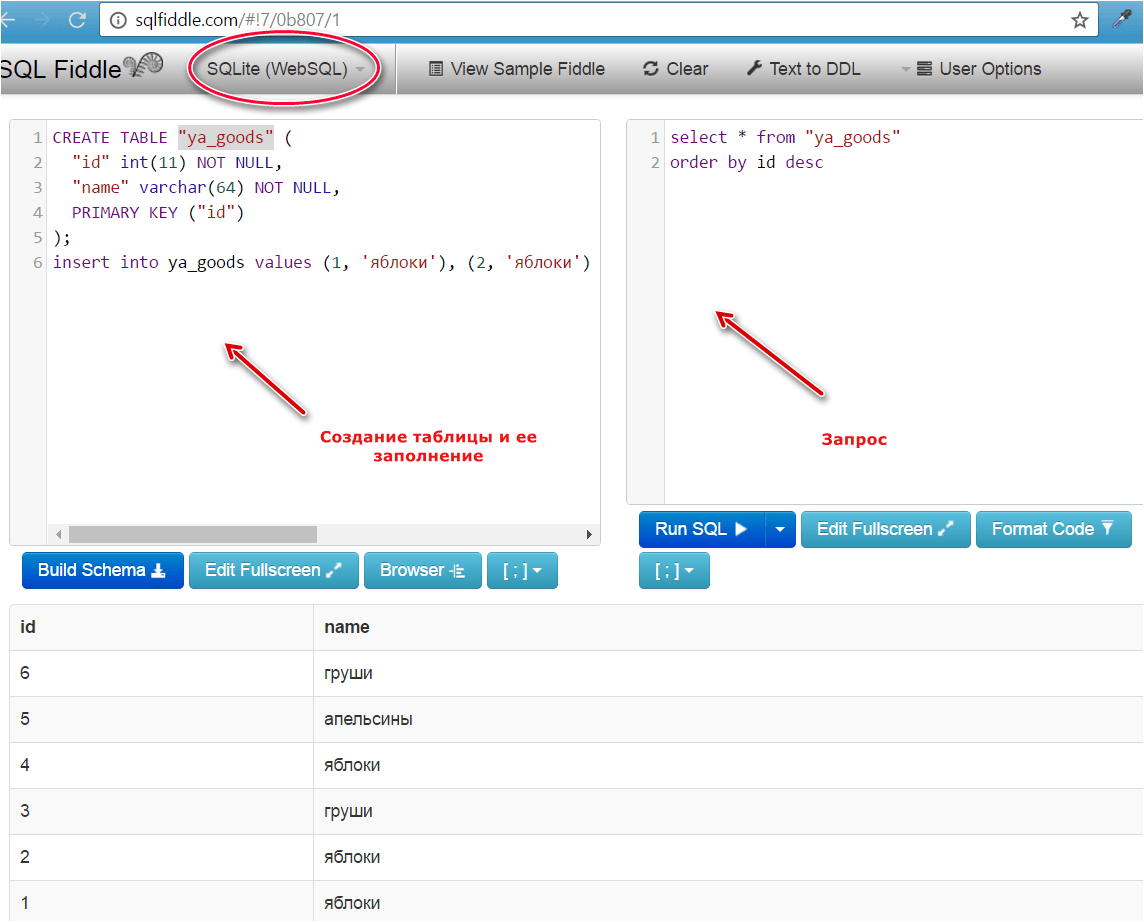
Теперь некоторые пункты рассмотрим подробнее.
Создание таблиц:
Пример: создайте сразу три таблицы (teachers, lessons и courses); добавьте по нескольку значений в каждую таблицу.
* для тех, кто незнаком с синтаксисом — просто скопировать полностью код и вставить в левое окошко сервиса
* урок по созданию таблиц в языке SQL
| /*teachers*/ CREATE TABLE `teachers` ( `id` INT (11 ) NOT NULL , `name` VARCHAR (25 ) NOT NULL , `code` INT (11 ) , `zarplata` INT (11 ) , `premia` INT (11 ) , PRIMARY KEY (`id` ) ) ; INSERT INTO teachers VALUES (1 , "Иванов" , 1 , 10000 , 500 ) , (2 , "Петров" , 1 , 15000 , 1000 ) , (3 , "Сидоров" , 1 , 14000 , 800 ) , (4 , "Боброва" , 1 , 11000 , 800 ) ; /*lessons*/ CREATE TABLE `lessons` ( `id` INT (11 ) NOT NULL , `tid` INT (11 ) , `course` VARCHAR (25 ) , `date` VARCHAR (25 ) , PRIMARY KEY (`id` ) ) ; INSERT INTO lessons VALUES (1 , 1 , "php" , "2015-05-04" ) , (2 , 1 , "xml" , "2016-13-12" ) ; /*courses*/ CREATE TABLE `courses` ( `id` INT (11 ) NOT NULL , `tid` INT (11 ) , `title` VARCHAR (25 ) , `length` INT (11 ) , PRIMARY KEY (`id` ) ) ; INSERT INTO courses VALUES (1 , 1 , "php" , 54 ) , (2 , 1 , "xml" , 72 ) , (3 , 2 , "sql" , 25 ) ; |
/*teachers*/ CREATE TABLE `teachers` (`id` int(11) NOT NULL, `name` varchar(25) NOT NULL, `code` int(11), `zarplata` int(11), `premia` int(11), PRIMARY KEY (`id`)); insert into teachers values (1, "Иванов",1,10000,500), (2, "Петров",1,15000,1000) ,(3, "Сидоров",1,14000,800), (4,"Боброва",1,11000,800); /*lessons*/ CREATE TABLE `lessons` (`id` int(11) NOT NULL, `tid` int(11), `course` varchar(25), `date` varchar(25), PRIMARY KEY (`id`)); insert into lessons values (1,1, "php","2015-05-04"), (2,1, "xml","2016-13-12"); /*courses*/ CREATE TABLE `courses` (`id` int(11) NOT NULL, `tid` int(11), `title` varchar(25), `length` int(11), PRIMARY KEY (`id`)); insert into courses values (1,1, "php",54), (2,1, "xml",72), (3,2, "sql",25);
В результате получим таблицы с данными:
Отправка запроса:
Для того чтобы протестировать работоспособность сервиса, добавьте в правое окошко код запроса.
Пример: при помощи запроса выберите все данные из таблицы teachers, касаемые учителя с фамилией Иванов
На дальнейших уроках SQL будет использоваться та же схема, поэтому необходимо будет просто копировать схему и вставлять в левое окно сервиса.
Для онлайн визуализации схемы базы данных можно воспользоваться сервисом https://dbdesigner.net/ :
- Создать свой аккаунт (войти в него, если уже есть).
- Щелкнуть по кнопке Go to Application .
- Меню Schema -> Import .
- Скопировать и вставить в появившееся окно код создания и заполнения таблиц базы данных

Программирование на T - SQL
Синтаксис и соглашения T-SQL
Правила формирования идентификаторов
Все объекты в SQL Server имеют имена (идентификаторы). Примерами объектов являются таблицы, представления, хранимые процедуры и т.д. Идентификаторы могут включать до 128 символов, в частности, буквы, символы _ @ $ # и цифры.
Первый символ всегда должен быть буквенным. Для переменных и временных таблиц используются специальные схемы именования. Имя объекта не может содержать пробелов и совпадать с зарезервированным ключевым словом SQL Server, независимо от используемого регистра символов. Путем заключения идентификаторов в квадратные скобки, в именах объектов можно использовать запрещенные символы.
Завершение инструкции
Стандарт ANSI SQL требует помещения в конце каждой инструкции точки с запятой. В то же время при программировании на языке T-SQL точка с запятой не обязательна.
Комментарии
Язык T-SQL допускает использование комментариев двух стилей: ANCI и языка С. Первый из них начинается с двух дефисов и заканчивается в конце строки:
Это однострочный комментарий стиля ANSI
Также комментарии стиля ANSI могут вставляться в конце строки инструкции:
SELECT CityName – извлекаемые столбцы
FROM City – исходная таблица
WHERE IdCity = 1; -- ограничение на строки
Редактор SQL может применять и удалять комментарии во всех выделенных строках. Для этого нужно выбрать соответствующие команды в меню Правка или на панели инструментов.
Комментарии стиля языка С начинаются с косой черты и звездочки (/*) и заканчиваются теми же символами в обратной последовательности. Этот тип комментариев лучше использовать для комментирования блоков строк, таких как заголовки или большие тестовые запросы.
многострочного
комментария
Одним из главных достоинств комментариев стиля С является то, что многострочные запросы в них можно выполнять, даже не раскомментируя.
Пакеты T-SQL
Запросом называют одну инструкцию T-SQL, а пакетом - их набор. Вся последовательность инструкций пакета отправляется серверу из клиентских приложений как одна цельная единица.
SQL Server рассматривает весь пакет как рабочую единицу. Наличие ошибки хотя бы в одной инструкции приведет к невозможности выполнения всего пакета. В то же время грамматический разбор не проверяет имена объектов и схем, так как сама схема может измениться в процессе выполнения инструкции.
Файл сценария SQL и окно анализатора запросов (Query Analyzer) может содержать несколько пакетов. В данном случае все пакеты разделяют ключевые слова терминаторов. По умолчанию этим ключевым словом является GO, и оно должно быть единственным в строке. Все другие символы (даже комментарии) нейтрализуют разделитель пакета.
Отладка T-SQL
Когда редактор SQL обнаруживает ошибку, он отображает ее характер и номер строки в пакете. Дважды щелкнув на ошибке, можно сразу же переместиться к соответствующей строке.
В утилиту Management Studio версии SQL Server 2005 не включен отладчик языка T-SQL, - он присутствует в пакете Visual Studio.
SQL Server предлагает несколько команд, облегчающих отладку пакетов. В частности, команда PRINT отправляет сообщение без генерации результирующего набора данных. Команду PRINT можно использовать для отслеживания хода выполнения пакета. Когда анализатор запросов находится в режиме сетки, выполните следующий пакет:
SELECT CityName
FROM City
WHERE IdCity = 1;
PRINT "Контрольная точка" ;
Результирующий набор данных отобразится в сетке и будет состоять из одной строки. В то же время во вкладке «Сообщения» отобразится следующий результат:
(строк обработано: 1)
Контрольная точка
Переменные
Переменные T-SQL создаются с помощью команды DECLARE, имеющей следующий синтаксис:
DECLARE @Имя_Переменной Тип_Данных [,
@Имя_Переменной Тип_Данных, …]
Все имена локальных переменных должны начинаться символом @. Например, для объявления локальной переменной UStr, которая хранит до 16 символов Unicode, можно использовать следующую инструкцию:
DECLARE @UStr varchar (16)
Используемые для переменных типы данных в точности совпадают с существующими в таблицах. В одной команде DECLARE через запятую может быть перечислено несколько переменных. В частности в следующем примере создаются две целочисленные переменные a и b:
DECLARE
@a int ,
@b int
Область определения переменных (т.е. срок их жизни) распространяется только на текущий пакет. По умолчанию только что созданные переменные содержат пустые значения NULL и до включения в выражения должны быть инициализированы.
Задание значений переменных
В настоящее время в языке SQL предусмотрены два способа задания значения переменной - для этой цели можно использовать оператор SELECT или SET. С точки зрения выполняемых функций эти операторы действуют почти одинаково, не считая того, что оператор SELECT позволяет получить исходное присваиваемое значение из таблицы, указанной в операторе SELECT.
Оператор SET обычно используется для задания значений переменных в такой форме, какая более часто встречается в процедурных языках. В качестве типичных примеров применения этого оператора можно указать следующие:
SET @a = 1;
SET @b = @a * 1.5
Обратите внимание на то, что во всех этих операторах непосредственно осуществляются операции присваивания, в которых используются либо явно заданные значения, либо другие переменные. С помощью оператора SET невозможно присвоить переменной значение, полученное с помощью запроса; запрос должен быть выполнен отдельно и только после этого полученный результат может быть присвоен с помощью оператора SET. Например, попытка выполнения такого оператора вызывает ошибку:
DECLARE @c int
SET @c = COUNT (*) FROM City
SELECT @c
а следующий оператор выполняется вполне успешно:
DECLARE @c int
SET @c = (SELECT COUNT (*) FROM City)
SELECT @c
Оператор SELECT обычно используется для присваивания значений переменным, если источником информации, которая должна быть сохранена в переменной, является запрос. Например, действия, осуществляемые в приведенном выше коде, гораздо чаще реализуются с помощью оператора SELECT:
DECLARE @c int
SELECT @c = COUNT (*) FROM City
SELECT @c
Обратите внимание на то, что данный код немного понятнее (в частности, он более лаконичен, хотя и выполняет те же действия).
Таким образом, можно, сформулировать следующее общепринятое соглашение по использованию того и другого оператора.
Оператор SET используется, если должна быть выполнена простая операция присваивания значения переменной, т.е. если присваиваемое значение уже задано явно в форме определенного значения или в виде какой-то другой переменной.
- Оператор SELECT применяется, если присваивание значения переменной должно быть основано на запросе.
Использование переменных в запросах SQL
Одним из полезных свойств языка T-SQL является то, что переменные могут использоваться в запросах без необходимости создания сложных динамических строк, встраивающих переменные в программный код. Динамический SQL продолжает свое существование, но одиночное значение можно изменить проще - с помощью переменной.
Везде, где в запросе может использоваться выражение, может использоваться и переменная. В следующем примере продемонстрировано использование переменной в предложении WHERE:
DECLARE @IdProd int ;
SET @IdProd = 1;
SELECT
FROM Product
WHERE IdProd = @IdProd;
Глобальные системные переменные
В SQL Server имеется более тридцати глобальных переменных, не имеющих параметров, которые определяются и поддерживаются системой. Все глобальные переменные имеют префикс в виде двух символов @. Вы можете извлечь значение любой из них с помощью простого запроса SELECT, как в следующем примере:
SELECT @@CONNECTIONS
Здесь используется глобальная переменная @@CONNECTIONS для извлечения количества подключений к SQL Server со времени запуска программы.
Среди наиболее часто применяемых системных переменных можно отметить следующие:
- @@ERROR - Содержит номер ошибки, возникшей при выполнении последнего оператора T-SQL в текущем соединении. Если ошибка не обнаружена, содержит 0. Значение этой системной переменной переустанавливается после выполнения каждого очередного оператора. Если требуется сохранить содержащееся в ней значение, то это значение следует переносить в локальную переменную сразу же после выполнения оператора, для которого должен быть сохранен код ошибки.
- @@IDENTITY - Содержит последнее идентификационное значение, вставленное в базу данных в результате выполнения последнего оператора INSERT. Если в последнем операторе INSERT не произошла выработка идентификационного значения, системная переменная @@IDENTITY содержит NULL. Это утверждение остается справедливым, даже если отсутствие идентификационного значения было вызвано аварийным завершением при выполнении оператора. А если с помощью одного оператора осуществляется несколько операций вставки, этой системной переменной присваивается только последнее идентификационное значение.
- @@ROWCOUNT - Одна из наиболее широко используемых системных переменных. Возвращает информацию о количестве строк, затронутых последним оператором. Обычно применяется для контроля ошибок, отличных от тех, которые относятся к категории ошибок этапа прогона программы. Например, если в программе обнаруживается, что после вызова на выполнение оператора DELETE с конструкцией WHERE количество затронутых строк равно нулю, то можно сделать вывод, что произошло нечто непредвиденное. После этого сообщение об ошибке может быть активизировано вручную.
! Следует отметить, что с версии SQL Server 2000 глобальные переменные принято называть функциями. Название глобальные сбивало пользователей с толку, позволяя думать, что область действия таких переменных шире, чем у локальных. Глобальным переменным часто ошибочно приписывалась возможность хранить информацию, независимо от того, включена она в пакет либо нет, что, естественно, не соответствовало действительности.
Средства управления потоком команд. Программные конструкции
В языке T-SQL предусмотрена большая часть классических процедурных средств управления ходом выполнения программы, в т.ч. условная конструкция и циклы.
Оператор IF. . . ELSE
Операторы IF. . .ELSE действуют в языке T-SQL в основном так же, как и в любых других языках программирования. Общий синтаксис этого оператора имеет следующий вид:
IF Логическое выражение
SQL инструкция I BEGIN Блок SQL инструкций END
SQL инструкция | BEGIN Блок SQL инструкций END]
В качестве логического выражения может быть задано практически любое выражение, результат вычисления которого приводит к возврату булева значения.
Следует учитывать, что выполняемым по условию считается только тот оператор, который непосредственно следует за оператором IF (ближайшим к нему). Вместо одного оператора можно предусмотреть выполнение по условию нескольких операторов, объединив их в блок кода с помощью конструкции BEGIN…END.
В приведенном ниже примере условие IF не выполняется, что предотвращает выполнение следующего за ним оператора.
IF 1 = 0
PRINT "Первая строка"
PRINT "Вторая строка"
Необязательная команда ELSE позволяет задать инструкцию, которая будет выполнена в случае, если условие IF не будет выполнено. Подобно IF, оператор ELSE управляет только непосредственно следующей за ним командой или блоком кода заключенным между BEGIN…END.
Несмотря на то, что оператор IF выглядит ограниченным, его предложение условия может включать в себя мощные функции, подобно предложению WHERE. В частности это выражения IF EXISTS().
Выражение IF EXISTS() использует в качестве условия наличие какой-либо строки, возвращенной инструкцией SELECT. Так как ищутся любые строки, список столбцов в инструкции SELECT можно заменить звездочкой. Этот метод работает быстрее, чем проверка условия @@ROWCOUNT>0, потому что не требуется подсчет общего количества строк. Как только хотя бы одна строка удовлетворяет условию IF EXISTS(), запрос может продолжать выполнение.
В следующем примере выражение IF EXISTS используется для проверки наличия у клиента с кодом 1 каких-либо заказов перед удалением его из базы. Если по данному клиенту есть информация хотя бы по одному заказу, удаление не производится.
IF EXISTS (SELECT * FROM WHERE IdCust = 1)
PRINT "Невозможно удалить клиента поскольку в базе имеются связанные с ним записи"
ELSE
WHERE IdCust = 1
PRINT "Удаление произведено успешно"
Операторы WHILE, BREAK и CONTINUE
Оператор WHILE в языке SQL действует во многом так же, как и в других языках, с которыми обычно приходится работать программисту. По сути, в этом операторе до начала каждого прохода по циклу проверяется некоторое условие. Если перед очередным проходом по циклу проверка условия приводит к получению значения TRUE, осуществляется проход по циклу, в противном случае выполнение оператора завершается.
Оператор WHILE имеет следующий синтаксис:
WHILE Логическое выражение
SQL инструкция I
Блок SQL инструкций
Безусловно, с помощью оператора WHILE можно обеспечить выполнение в цикле только одного оператора (по аналогии с тем, как обычно используется оператор IF), но на практике конструкции WHILE, за которыми не следует блок BEGIN. . .END, соответствующий полному формату оператора, встречаются редко.
Оператор BREAK позволяет немедленно выйти из цикла, не ожидая того, как будет выполнен проход до конца цикла и произойдет повторная проверка условного выражения.
Оператор CONTINUE позволяет прервать отдельную итерацию цикла. Кратко можно описать действие оператора CONTINUE так, что он обеспечивает переход в начало цикла WHILE. Сразу после обнаружения оператора CONTINUE в цикле, независимо от того, где он находится, происходит переход в начало цикла и повторное вычисление условного выражения (а если значение этого выражения больше не равно TRUE, осуществляется выход из цикла).
Следующий короткий сценарий демонстрирует использование оператора WHILE для создания цикла:
DECLARE @Temp int ;
SET @Temp = 0;
WHILE @Temp < 3
BEGIN
PRINT @Temp;
SET @Temp = @Temp + 1;
Здесь в цикле целочисленная переменная @Temp увеличивается с 0 до 3 и на каждой итерации ее значение выводится на экран.
Оператор RETURN
Оператор RETURN используется для останова выполнения пакета, а следовательно, хранимой процедуры и триггера (рассматриваются в следующих лабораторных занятиях).
sql часто называют языком эсперанто для систем управления базами данных (СУБД). Действительно, в мире нет другого языка для работы с базами данных (БД), который бы настолько широко использовался в программах. Первый стандарт sol появился в 1986 г. и к настоящему времени завоевал всеобщее признание. Его можно использовать даже при работе с нереляционными СУБД. В отличие от других программных средств, таких, как языки Си и Кобол, являющихся прерогативой программистов-профессионалов, sql применяется специалистами из самых разных областей. Программисты, администраторы СУБД, бизнес-аналитики — все они с успехом обрабатывают данные с помощью sql. Знание этого языка полезно всем, кому приходится иметь дело с БД.
В этой статье мы рассмотрим основные понятия sql. Расскажем его предысторию (и развеем попутно несколько мифов). Вы познакомитесь с реляционной моделью и сможете приобрести первые навыки работы с sql, что поможет в дальнейшем освоении языка.
Трудно ли изучить sql? Это зависит от того, насколько глубоко вы собираетесь вникать в суть. Для того чтобы стать профессионалом, придется изучить очень многое. Язык sql появился в 1974 г. как предмет небольшой исследовательской работы, состоявшей из 23 страниц, и с тех пор прошел долгий путь развития. Текст действующего ныне стандарта — официального документа "the international standard database language sql" (обычно называемого sql-92) — содержит свыше шести сотен страниц, однако в нем ничего не говорится о конкретных особенностях версий sol, реализованных в СУБД фирм microsoft, oracle, sybase и др. Язык настолько развит и разнообразен, что лишь простое перечисление его возможностей потребует нескольких журнальных статей, а если собрать все, что написано на тему sol, то получится многотомная библиотека.
Однако для обычного пользователя совсем не обязательно знать sql целиком и полностью. Как туристу, оказавшемуся в стране, где говорят на непонятном языке, достаточно выучить лишь несколько употребительных выражений и правил грамматики, так и в sql — зная немногое, можно получать множество полезных результатов. В этой статье мы рассмотрим основные команды sql, правила задания критериев для отбора данных и покажем, как получать результаты. В итоге вы сможете самостоятельно создавать таблицы и вводить в них информацию, составлять запросы и работать с отчетами. Эти знания могут стать базой для дальнейшего самостоятельного освоения sql.
Что такое sql?
sql — это специализированный непроцедурный язык, позволяющий описывать данные, осуществлять выборку и обработку информации из реляционных СУБД. Специализированность означает, что sol предназначен лишь для работы с БД; нельзя создать полноценную прикладную систему только средствами этого языка — для этого потребуется использовать другие языки, в которые можно встраивать sql-команды. Поэтому sql еще называют вспомогательным языковым средством для обработки данных. Вспомогательный язык используется только в комплексе с другими языками.
В прикладном языке общего назначения обычно имеются средства для создания процедур, а в sql их нет. С его помощью нельзя указать, каким образом должна выполняться некоторая задача, а можно лишь определить, в чем именно она заключается. Другими словами, при работе с sql нас интересуют результаты, а не процедуры для их получения.
Наиболее существенным свойством sql является возможность доступа к реляционным БД. Многие даже считают, что выражения "БД, обрабатываемая средствами sql" и "реляционная БД" — синонимы. Однако скоро вы убедитесь, что между ними имеется разница. В стандарте sql-92 даже нет термина отношение (relation).
Что такое реляционная СУБД?
Если не вдаваться в подробности, то реляционная СУБД — это система, основанная на реляционной модели управления данными.
Понятие реляционной модели было впервые предложено в работе д-ра Е. Ф. Кодда, опубликованной в 1970 г. В ней был описан математический аппарат для структуризации данных и управления ими, а также предложена абстрактная модель для представления любой реальной информации. До этого при использовании БД требовалось учитывать конкретные особенности хранения в ней информации. Если внутренняя структура БД изменялась (например, с целью повышения быстродействия), приходилось перерабатывать прикладные программы, даже если на логическом уровне никаких изменений не происходило. Реляционная модель позволила отделить частные особенности хранения данных от уровня прикладной программы. В самом деле, модель никак не описывает способы хранения информации и доступа к ней. Учитывается лишь то, как эта информация воспринимается пользователем. Благодаря появлению реляционной модели качественно изменился подход к управлению данными: из искусства оно превратилось в науку, что привело к революционному развитию отрасли.
Основные понятия реляционной модели
Согласно реляционной модели, отношение (relation) — это некоторая таблица с данными. Отношение может иметь один или несколько атрибутов (признаков), соответствующих столбцам этой таблицы, и некоторое множество (возможно, пустое) данных, представляющих собой наборы этих атрибутов (их называют n-арными кортежами, или записями) и соответствующих строкам таблицы.
Для любого кортежа значения атрибутов должны принадлежать так называемым доменам. Фактически доменом является некоторый набор данных, который задает множество всех допустимых значений.
Давайте рассмотрим пример. Пусть имеется домен ДниНедели, содержащий значения от Понедельник до Воскресенье. Если отношение имеет атрибут ДеньНедели, соответствующий этому домену, то в любом кортеже отношения в столбце ДеньНедели должно присутствовать одно из перечисленных значений. Появление значений Январь или Кошка не допускается.
Обратите внимание: атрибут обязательно должен иметь одно из допустимых значений. Задание сразу нескольких значений запрещено. Таким образом, помимо требования принадлежности значений атрибута некоторому домену, должно соблюдаться условие его атомарности. Это означает, что для этих значений недопустима декомпозиция, т. е. нельзя разбить их на более мелкие части, не потеряв основного смысла. Например, если бы значение атрибута одновременно содержало Понедельник и Вторник, то можно было бы выделить две части, сохранив первоначальный смысл — ДеньНедели; следовательно, это значение атрибута не является атомарным. Однако если попробовать разбить значение "Понедельник" на части, то получится набор из отдельных букв — от "П" до "К"; исходный смысл утерян, поэтому значение "Понедельник" является атомарным.
Отношения обладают и другими свойствами. Наиболее значимое из них — математическое свойство замкнутости операций. Это означает, что в результате выполнения любой операции над отношением должно появляться новое отношение. Это свойство позволяет при выполнении математических операций над отношениями получать предсказуемые результаты. Кроме того, появляется возможность представлять операции в виде абстрактных выражений с разными уровнями вложенности.
В своей исходной работе д-р Кодд определил набор из восьми операторов, получивший название реляционной алгебры. Четыре оператора — объединение, логическое умножение, разность и Декартово произведение — были перенесены из традиционной теории множеств; остальные операторы были созданы специально для обработки отношений. В последующих работах д-ра Кодда, Криса Дейта и других исследователей были предложены дополнительные операторы. Далее в этой статье будут рассмотрены три реляционных оператора — продукция (project), ограничения (select, или restrict) и слияние (join).
sql и реляционная модель
Теперь, когда вы познакомились с реляционной моделью, давайте забудем о ней. Конечно, не навсегда, а лишь для того, чтобы объяснить следующее: хотя именно предложенная д-ром Коддом реляционная модель была использована при разработке sql, между ними нет полного или буквального соответствия (это одна из причин, почему в стандарте sql-92 отсутствует термин отношение). Например, понятия таблица sql и отношение не являются равнозначными, потому что в таблицах может быть сразу несколько одинаковых строк, тогда как в отношениях появление идентичных кортежей не разрешено. К тому же в sql не предусмотрено использование реляционных доменов, хотя в некоторой степени их роль играют типы данных (некоторые влиятельные сторонники реляционной модели предпринимают сейчас попытку добиться включения в будущий стандарт sql реляционных доменов).
К сожалению, несоответствие между sql и реляционной моделью породило множество недоразумений и споров за прошедшие годы. Но так как основная тема статьи — изучение sql, а не реляционной модели, эти проблемы здесь не рассматриваются. Просто следует запомнить, что между терминами, применяемыми в sql и в реляционной модели, имеются различия. Далее в статье будут использоваться только термины, принятые в sql. Вместо отношений, атрибутов и кортежей будем применять их sql-аналоги: таблицы, столбцы и строки.
Статический и динамический sql
Возможно, вам уже знакомы такие термины, как статический и динамический sql. sql-запрос является статическим, если он компилируется и оптимизируется на стадии, предшествующей выполнению программы. Мы уже упоминали одну из форм статического sql, когда говорили о встраивании sql-команд в программы на Си или Коболе (для таких выражений существует еще другое название — встроенный sql). Как вы, наверное, догадываетесь, динамический sql-запрос компилируется и оптимизируется в ходе исполнения программы. Как правило, обычные пользователи применяют именно динамический sql, позволяющий создавать запросы в соответствии с сиюминутными нуждами. Один из вариантов изпользования динамических sql-запросов — их интерактивный или непосредственный вызов (существует даже специальный термин — directsql), когда отправляемые на обработку запросы вводятся в интерактивном режиме с терминала. Между статическим и динамическим sql имеются определенные различия в синтаксисе применяемых конструкций и особенностях исполнения, однако эти вопросы выходят за рамки статьи. Отметим лишь, что для ясности понимания примеры даются в форме direct sql-запросов, поскольку это позволяет научиться использовать sql не только программистам, но и большинству конечных пользователей.
Как изучать sql
Теперь вы готовы к написанию своих первых sql-запросов. Если у вас имеется доступ к БД через sql и вы захотите воспользоваться нашими примерами на практике, то учтите следующее: вы должны входить в систему как пользователь с неограниченными полномочиями и вам потребуются программные средства интерактивной обработки sql-запросов (если речь идет о сетевой БД, следует переговорить с администратором БД о предоставлении вам соответствующих прав). Если доступа к БД через sql нет — не огорчайтесь: все примеры очень простые и в них можно разобраться "всухую", без выхода на машину.
Для того чтобы выполнить какие-либо действия в sql, следует выполнить выражение на языке sql. Встречается несколько типов выражений, однако среди них можно выделить три основные группы: ddl-команды (data definition language — язык описания данных), dml-команды (data manipulation language — язык манипуляций с данными) и средства контроля за данными. Таким образом, в sql в каком-то смысле объединены три различных языка.
Команды языка описания данных
Начнем с одной из основных ddl-команд — create table (Создать таблицу). В sql бывают таблицы нескольких типов, основными являются два типа: базовые (base) и выборочные (views). Базовыми являются таблицы, относящиеся к реально существующим данным; выборочные — это "виртуальные" таблицы, которые создаются на основе информации, получаемой из базовых таблиц; но для пользователей формы выглядят как обычные таблицы. Команда create table предназначена для создания базовых таблиц.
В команде create table следует задать название таблицы, указать список столбцов и типы содержащихся в них данных. В качестве параметров могут присутствовать также другие необязательные элементы, однако сначала давайте рассмотрим только основные параметры. Покажем простейшую синтаксическую форму для этой команды:
create table ИмяТаблицы (Столбец ТипДанных) ;
create и table — это ключевые слова sql; ИмяТаблицы, Столбец и ТипДанных — это формальные параметры, вместо которых пользователь каждый раз вводит фактические значения. Параметры Столбец и ТипДанных заключены в круглые скобки. В sql круглые скобки обычно используются для группировки отдельных элементов. В данном случае они позволяют объединить определения для столбца. Стоящий в конце знак "точка с запятой" является разделителем команд. Он должен завершать любое выражение на языке sql.
Рассмотрим пример. Пусть нужно создать таблицу для хранения данных обо всех встречах (appointments). Для этого в sql следует ввести команду:
create table appointments (appointment_date date) ;
После выполнения этой команды будет создана таблица с именем appointments, где имеется один столбец appointment_date, в котором могут записываться данные типа date. Поскольку на текущий момент данные еще не вводились, количество строк в таблице равно нулю (с помощью команды create table только дается определение таблицы; реальные значения вводятся командой insert, которая рассматривается далее).
Параметры appointments и appointment_date называются идентификаторами, поскольку они задают имена для конкретных объектов БД, в данном случае — имена для таблицы и столбца соответственно. В sql встречаются идентификаторы двух типов: обычные (regular) и выделенные (delimited). Выделенные идентификаторы заключаются в двойные кавычки, и в них учитывается регистр используемых символов. Обычные идентификаторы не выделяются никакими ограниченными символами, в их написании регистр не учитывается. В этой статье применяются только обычные идентификаторы.
Символы, используемые для построения идентификаторов, должны удовлетворять определенным правилам. В обычных идентификаторах могут использоваться только буквы (не обязательно латинские, но и других алфавитов), цифры и символ подчеркивания. Идентификатор не должен содержать знаков пунктуации, пробелов или специальных символов (#, @, % или!); кроме того, он не может начинаться с цифры или знака подчеркивания. Для идентификаторов можно использовать отдельные ключевые слова sql, но делать это не рекомендуется. Идентификатор предназначен для обозначения некоторого объекта, поэтому у него должно быть уникальное (в рамках определенного контекста) имя: нельзя создать таблицу с именем, которое уже встречается в БД; в одной таблице нельзя иметь столбцы с одинаковыми именами. Кстати, имейте в виду, что appointments и appointments — это одинаковые имена для sql. Одним лишь изменением регистра букв создать новый идентификатор нельзя.
Хотя таблица может иметь всего один столбец, на практике обычно требуются таблицы с несколькими столбцами. Команда для создания такой таблицы в общем виде выглядит так:
create table ИмяТаблицы (Столбец ТипДанных [ { , Столбец ТипДанных } ]) ;
Квадратные скобки использованы для обозначения необязательных элементов, фигурные содержат элементы, которые могут представлять собой перечень однопутных конструкций (при вводе реальной sql-команды ни те ни другие скобки не ставятся). Такой синтаксис позволяет задать любое число столбцов. Обратите внимание, что перед вторым элементом стоит запятая. Если в списке имеется несколько параметров, то они отделяются друг от друга запятыми.
create table appointments2 (appointment_date date , appointment_time time , description varchar (256)) ;
Данная команда создает таблицу appointments2 (новая таблица должна иметь иное имя, так как таблица appointments уже присутствует в БД). Как и в первой таблице, в ней имеется столбец appointment_date для записи даты встреч; кроме того, появился столбец appointment_time для записи времени этих встреч. Параметр description (описание) является текстовой строкой, где может содержаться до 256 символов. Для этого параметра указан тип varchar (сокращение от character varying), поскольку заранее не известно, сколько места потребуется для записи, но ясно, что описание займет не более 256 символов. При описании параметро в типа символьная строка (и некоторых других типов) указывается длина параметра. Ее значение задается в круглых скобках справа от названия типа.
Возможно, вы обратили внимание, что в двух рассмотренных примерах запись команды оформлена по-разному. Если в первом случае команда полностью размещена в одной строке, то во втором после первой открытой круглой скобки запись продолжена с новой строки, и определение каждого следующего столбца начинается с новой строки. В sql нет специальных требований к оформлению записи. Разбиение записи на строки делает ее чтение удобнее. Язык sql позволяет при написании команд не только разбивать команду по строкам, но и вставлять отступы в начале строк и пробелы между элементами записи.
Теперь, когда вы знаете основные правила, давайте рассмотрим более сложный пример создания таблицы с несколькими столбцами. В начале статьи была показана таблица employees (Сотрудники). В ней содержатся следующие столбцы: фамилия, имя, дата приема на работу, подразделение, категория и зарплата за год. Для определения этой таблицы используется следующая команда sql:
create table employees (last_name character (13) not null, first_name character (10) not null, hire_date date , branch_office character (15) , grade_level smallint , salary decimal (9 , 2)) ;
В команде встречаются несколько новых элементов. Прежде всего, это выражение not null, стоящее в конце определения столбцов last_name и first_name. С помощью подобных конструкций задаются требования, подлежащие обязательному соблюдению. В данном случае указано, что поля last_name и first_name должны обязательно заполняться при вводе; оставлять эти столбцы пустыми нельзя (это вполне логично: как можно идентифицировать сотрудника, не зная его имени?).
Кроме того, в примере присутствуют три новых типа данных: character, smallint и decimal. До сих пор мы почти не говорили о типах. Хотя в sql нет реляционных доменов, однако имеется набор основных типов данных. Эта информация используется при выделении памяти и сравнении величин; в определенной степени сужает список возможных значений при вводе, однако контроль типов в sql менее строгий, чем в других языках.
Все имеющиеся в sql типы данных можно разбить на шесть групп: символьные строки, точные числовые значения, приближенные числовые значения, битовые строки, датовремя и интервалы. Мы перечислили все разновидности, однако в этой статье подробно будут рассматриваться лишь отдельные из них (битовые строки, например, не представляют особого интереса для обычных пользователей).
Кстати, если вы подумали, что датовремя — это опечатка, то ошиблись. К данной группе (datetime) относится большинство используемых в sql типов данных, связанных со временем (такие параметры, как временные интервалы, выделены в отдельную группу). В предыдущем примере уже встречались два типа данных из группы датовремя — date и time.
Следующий тип данных, с которым вы уже знакомы, — character varying (или просто varchar); он относится к группе символьных строк. Если varchar служит для хранения строк переменной длины, то встретившийся в третьем примере тип char предназначен для записи строк, имеющих фиксированное число символов. Например, в столбце last_name будут записываться строки из 13 символов вне зависимости от реально вводимых фамилий, будь то poe или penworth-chickering (в случае с poe оставшиеся 10 символов заполнятся пробелами).
С точки зрения пользователя, varchar и char имеют одинаковый смысл. Зачем нужно было вводить два типа? Дело в том, что на практике обычно приходится искать компромисс между быстродействием и экономией пространства на диске. Как правило, применение строк с фиксированной длиной дает некоторый выигрыш в скорости доступа, однако при слишком большой длине строк пространство на диске расходуется неэкономно. Если в appointments2 для каждой строки комментария резервировать по 256 символов, то это может оказаться нерационально; чаще всего строки будут значительно короче. С другой стороны, фамилии также имеют разную длину, но для них, как правило, требуется около 13 символов; в этом случае потери будут минимальными. Существует хорошее правило: если известно, что длина строки меняется незначительно либо она сравнительно невелика, то используйте char; в остальных случаях — varchar.
Следующие два новых типа данных — smallint и decimal — относятся к группе точных числовых значений. smallint — это сокращенное название от small integer (малое целое). В sql также предусмотрен тип данных integer. Наличие двух схожих типов и в этом случае объясняется соображением экономии пространства. В нашем примере значения параметра grade_level могут быть представлены с помощью двузначного числа, поэтому использован тип smallint; однако на практике не всегда известно, какие максимальные значения могут быть у параметров. Если такой информации нет, то применяйте integer. Реальный объем, выделяемый для хранения параметров типа smallint и integer, и соответствующий диапазон значений для этих параметров индивидуальны для каждой платформы.
Тип данных decimal, обычно используемый для учета финансовых показателей, позволяет задать шаблон с требуемым числом десятичных знаков. Поскольку этот тип служит для точной числовой записи, он гарантирует точность при выполнении математических операций над десятичными данными. Если для десятичных значений использовать типы данных из группы приближенной числовой записи, например float (floating point number — число с плавающей точкой), это приведет к погрешностям округления, поэтому для финансовых расчетов этот вариант не подходит. Для определения параметров типа decimal используется следующая форма записи:
где p — это число десятичных знаков, d — количество разрядов после запятой. Вместо p следует записывать общее число значащих цифр в используемых значениях, а вместо d — количество цифр после запятой.
Во врезке "Создание таблицы" показан полный вариант обобщенной записи команды create table. В нем присутствуют новые элементы и показан формат для всех рассмотренных типов данных (В принципе встречаются и другие типы данных, но пока мы их не рассматриваем).
На первых порах может показаться, что синтаксис sql-команд слишком сложен. Но вы легко в нем разберетесь, если внимательно изучили приведенные выше примеры. На схеме появился дополнительный элемент — вертикальная черта; он служит для разграничения альтернативных конструкций. Другими словами, при определении каждого столбца нужно выбрать подходящий тип данных (как вы помните, в квадратные скобки заключаются необязательные параметры, а в фигурные скобки — конструкции, которые могут повторяться многократно; в реальных sql-командах эти специальные символы не пишутся). В первой части схемы приведены полные названия для типов данных, во второй — их сокращенные названия; на практике можно использовать любые из них.
Первая часть статьи завершена. Вторая будет посвящена изучению dml-команд insert, select, update и delete. Также будут рассмотрены условия выборки данных, операторы сравнения и логические операторы, использование null-значений и троичная логика.
Создание таблицы. Синтаксис команды create table: в квадратных скобках указаны необязательные параметры, в фигурных — повторяющиеся конструкции.
create table table (column character (length) [ constraint ] | character varying (length) [ constraint ] | date [ constraint ] | time [ constraint ] | integer [ constraint ] | smallint [ constraint ] | decimal (precision, decimal places) [ constraint ] | float (precision) [ constraint ] [{ , column char (length) [ constraint ] | varchar (length) [ constraint ] | date [ constraint ] | time [ constraint ] | int [ constraint ] | smallint [ constraint ] | dec (precision, decimal places) [ constraint ] | float (precision) [ constraint ] }]) ;
Секрет названия sql
В начале 1970-х гг. в ibm приступили к практическому воплощению модели реляционных БД, предложенной д-ром Коддом. Дональд Чамберлин и группа других сотрудников подразделения перспективных исследований создали прототип языка, получивший название structured english query language (язык структурированных англоязычных запросов), или просто sequel. В дальнейшем он был расширен и подвергнут доработке. Новый вариант, предложенный ibm, получил название sequel/2. Его использовали как программный интерфейс (api) для проектирования первой реляционной системы БД фирмы ibm — system/r. Из соображений, связанных с правовыми нюансами, в ibm решили изменить название: вместо sequel/2 использовать sql (structured query language). Эту аббревиатуру часто произносят как "си-ку-эл".
Доступный в Интернете словарь Merriam-Webster определяет базу данных как большой набор данных , организованный специальным образом для обеспечения быстрого поиска и извлечения данных (например, с помощью компьютера).
Система управления базами данных (СУБД) , как правило, представляет собой комплект библиотек, приложений и утилит , освобождающих разработчика приложения от груза забот, касающихся деталей хранения и управления данными . СУБД также предоставляет средства поиска и обновления записей.
За многие годы для решения различных видов проблем хранения данных было создано множество СУБД.
Типы баз данных
В 1960-70-х годах разрабатывались базы данных, которые тем или иным способом решали проблему повторяющихся групп. Эти методы привели к созданию моделей систем управления базами данных. Основой для таких моделей, используемых и по сей день, послужили исследования, проводимые в компании IBM.
Одним из основополагающих факторов проектирования ранних СУБД была эффективность. Гораздо легче манипулировать записями базы данных, имеющими фиксированную длину или, по крайней мере, фиксированное количество элементов в записи (столбцов в строке). Так удается избежать проблемы повторяющихся групп. Тот, кто программировал на каком-либо процедурном языке, без труда поймет, что в этом случае можно прочитать каждую запись базы данных в простую структуру C. Однако в реальной жизни такие удачные ситуации встречаются редко, поэтому программистам приходится обрабатывать не так удобно структурированные данные.
База данных с сетевой структурой
Сетевая модель вводит в базы данных указатели - записи, содержащие ссылки на другие записи. Так, можно хранить запись для каждого заказчика. Каждый заказчик в течение некоторого времени разместил у нас множество заказов. Данные расположены так, что запись заказчика содержит указатель ровно на одну запись заказа. Каждая запись заказа содержит как данные по этому конкретному заказу, так и указатель на другую запись заказа. Тогда в приложении-конвертере валют, которым мы занимались ранее, можно было бы использовать структуру, которая выглядела бы примерно так (рис. 1.):
Рис. 1. Структура записей конвертера валют
Данные загружаются и получается связанный (отсюда и название модели – сетевая) список для языков (рис. 2):

Рис. 2. Связанный список
Два разных типа записей, представленные на рисунке, будут храниться отдельно, каждый - в своей собственной таблице.
Конечно же, было бы более целесообразно, если бы названия языков не повторялись в базе снова и снова. Вероятно, лучше ввести третью таблицу, в которой содержались бы языки и идентификатор (часто в этом качестве используется целое число), который бы использовался для ссылки на запись таблицы языков из записей другого типа. Такой идентификатор называется ключом.
У сетевой модели базы данных есть несколько важных преимуществ. Если нужно найти все записи одного типа, относящиеся к определенной записи другого типа (например, языки, на которых говорят в одной из стран), то можно сделать это очень быстро, следуя по указателям, начиная с указанной записи.
Есть, однако, и недостатки. Если нам нужен перечень стран, в которых говорят по-французски, придется пройти по ссылкам всех записей стран, и для больших баз данных такая операция будет выполняться очень медленно. Это можно исправить, создав другие связанные списки указателей специально для языков, но такое решение быстро становится слишком сложным и, конечно же, не является универсальным, поскольку необходимо заранее решить, как будут организованы ссылки.
К тому же, писать приложение, использующее сетевую модель базы данных, достаточно утомительно, потому что обычно ответственность за создание и поддержание указателей по мере обновления и удаления записей лежит на приложении.
Иерархическая модель базы данных
В конце 1960-х годов IBM использовала в СУБД IMS иерархическую модель построения базы. В этой модели проблема повторяющихся групп решалась за счет представления одних записей как состоящих из множеств других.
Это можно представить как «спецификацию материалов», которая применяется для описания составляющих сложного продукта. Например, машина состоит (скажем) из шасси, кузова, двигателя и четырех колес. Каждый из этих основных компонентов в свою очередь состоит из некоторых других. Двигатель включает в себя несколько цилиндров, головку цилиндра и коленчатый вал. Эти компоненты опять-таки состоят из более мелких; так мы доходим до гаек и болтов, которыми комплектуются любые составляющие автомобиля.
Иерархическая модель базы данных применяется до сих пор. Иерархическая СУБД способна оптимизировать хранение данных в том, что касается некоторых отдельных вопросов, например можно без труда определить, в каком автомобиле используется какая-то конкретная деталь.
Реляционная модель базы данных
Огромный скачок в развитии теории систем управления базами данных произошел в 1970 году, когда был опубликован доклад Е. Ф. Код- да (E. F. Codd) «Реляционная модель для больших разделяемых банков данных» («A Relational Model of Data for Large Shared Data Banks»), см. эту ссылку. В этом поистине революционном труде вводилось понятие отношений и было показано, как использовать таблицы для представления фактов, которые устанавливают отношения с объектами «реального мира» и, следовательно, хранят данные о них.
К этому времени уже стало очевидно, что эффективность, достижение которой первоначально являлось основополагающим при проектировании базы, не так важна, как целостность данных. Реляционная модель придает гораздо большее значение целостности данных, чем любая другая ранее применявшаяся модель.
Реляционную систему управления базами данных определяет набор правил. Во-первых, запись таблицы носит название «кортеж», и именно этот термин используется в части документации на PostgreSQL. Кортеж - это упорядоченная группа компонентов (или атрибутов), каждый из которых принадлежит определенному типу. Все кортежи построены по одному шаблону, во всех одинаковое количество компонентов одинаковых типов. Приведем пример набора кортежей:
{"France", "FRF", 6.56} {"Belgium", "BEF", 40.1}
Каждый из этих кортежей состоит из трех атрибутов: названия страны (строковый тип), валюты (строковый тип) и валютного курса (тип с плавающей точкой). В реляционной базе данных все записи, добавляемые в это множество (или таблицу), должны следовать этой же форме, поэтому записи, представленные ниже, не могут быть добавлены:
Более того, ни в одной таблице не может быть повторения кортежей. То есть в любой таблице реляционной базы данных повторяющиеся строки или записи не разрешены.
Такая мера может выглядеть как драконовская, поскольку может показаться, что для системы, которая хранит заказы, размещаемые клиентами, это означает, что один клиент не сможет заказать какой-то продукт дважды.
Каждый атрибут записи должен быть «атомарным», то есть представлять собой простую порцию информации, а не другую запись или список других аргументов. Кроме того, типы соответствующих атрибутов в каждой записи должны совпадать, как было показано выше. Технически это означает, что они должны быть получены из одного и того же набора значений или домена. Практически же все они должны быть или строками, или целыми числами, или числами с плавающей точкой, или же принадлежать какому-то другому типу, поддерживаему СУБД.
Атрибут, по которому отличают записи, во всем остальном идентичные, называется ключом. В некоторых случаях в качестве ключа может выступать комбинация из нескольких атрибутов.
Атрибут (или атрибуты), предназначенный для того, чтобы отличить некоторую запись таблицы от всех остальных записей этой таблицы (или, другими словами, сделать запись уникальной), называется первичным ключом. В реляционной базе данных каждое отношение (таблица) должно иметь первичный ключ, то есть что-то, что делало бы каждую запись отличной от всех остальных в этой таблице.
Последнее правило, определяющее структуру реляционной базы данных, - это ссылочная целостность. Такое требование объясняется тем, что в любой момент времени все записи базы данных должны иметь смысл. Разработчик приложения, взаимодействующего с базой данных, должен быть внимателен, он обязан убедиться, что его код не нарушает целостности базы. Представьте, что происходит при удалении клиента. Если клиент удаляется из отношения CUSTOMER, необходимо удалить и все его заказы из таблицы ORDERS. В противном случае останутся записи о заказах, которым не сопоставлен клиент.
В следующих моих блогах будет представлена более подробная теоретическая и практическая информация о реляционных базах данных. Пока же запомните, что реляционная модель построена на таких математических понятиях, как множества и отношения, и что при создании систем следует придерживаться определенных правил.

Языки запросов SQL и друие
Реляционные системы управления базами данных, конечно же, предоставляют способы добавления и обновления данных, но это не главное, сила таких систем заключается в том, что они предоставляют пользователю возможность задавать вопросы о хранимых данных на специальном языке запросов. В отличие от более ранних баз данных, которые специально проектировались так, чтобы отвечать на определенные типы вопросов, касающихся содержащейся в них информации, реляционные базы данных являются гораздо более гибкими и отвечают на вопросы, которые еще не были известны при создании базы.
Предложенная Коддом реляционная модель использует тот факт, что отношения определяют множества, а множества можно обрабатывать математически. Кодд предположил, что в запросах мог бы применяться такой раздел теоретической логики, как исчисление предикатов, на его основе и построены языки запросов. Такой подход обеспечивает беспрецедентную производительность поиска и выборки множеств данных.
Одним из первых был реализован язык запросов QUEL, он использовался в созданной в конце 1970х годов базе данных Ingres. Еще один язык запросов, в котором применялся другой метод, назывался QBE (Query By Example - запрос по примеру). Приблизительно в то же самое время группа, работающая в исследовательском центре IBM, разработала язык структурированных запросов SQL (Structured Query Language), это название обычно произносится как «сиквел».
SQL - это стандартный язык запросов , наиболее распространенным его определением является стандарт ISO/IEC 9075:1992, «Information Technology - Database Languages - SQL» (или, проще говоря, SQL92) и его американский аналог ANSI X3.135-1992, отличающийся от первого лишь несколькими страницами обложки. Эти стандарты заменили ранее существовавший SQL89. На самом деле есть и более поздний стандарт, SQL99, но он еще не получил распространения, к тому же большая часть обновлений не затрагивает ядро языка SQL.
Существуют три уровня соответствия SQL92: Entry SQL, Intermediate SQL и Full SQL. Самым распространенным является уровень «Entry», и PostgreSQL очень близок к такому соответствию, хотя есть и небольшие различия. Разработчики занимаются исправлением незначительных упущений, и с каждой новой версией PostgreSQL становится все ближе к стандарту.
В языке SQL три типа команд:
- Data Manipulation Language (DML) - язык манипулирования данными. Это та часть SQL, которая используется в 90% случаев. Она состоит из команд добавления, удаления, обновления и, что важнее всего, выборки данных из базы данных.
- Data Definition Language (DDL) - язык определения данных. Это команды для создания таблиц и управления другими аспектами базы данных, структурированными на более высоком уровне, чем относящиеся к ним данные.
- Data Control Language (DCL) - язык управления данными
Это набор команд, контролирующих права доступа к данным. Многие пользователи баз данных никогда не применяют такие команды, поскольку работают в больших компаниях, где есть специальный администратор базы данных (или даже несколько), который занимается управлением базой данных, в его функции входит и контроль за правами доступа.
SQL
SQL практически повсеместно признан стандартным языком запросов и, как уже упоминалось, описан во многих международных стандартах. В наши дни почти каждая СУБД в той или иной степени поддерживает SQL. Это способствует унификации, т. к. приложение, написанное с применением SQL в качестве интерфейса к базе данных, может быть перенесено и использоваться на другой базе, при этом стоимость такого переноса в терминах затраченного времени и прилагаемых усилий будет невелика.
Однако под давлением рынка производители баз данных вынуждены создавать отличающиеся друг от друга продукты. Так появилось несколько диалектов SQL, чему способствовало и то, что в стандарте, описывающем язык, не определены команды для многих задач администрирования базы данных, которые представляют собой необходимую и очень важную составляющую при использовании базы в реальном мире. Поэтому существуют различия между диалектами SQL, принятыми (например) в Oracle, SQL Server и PostgreSQL.
SQL будет описываться на протяжении всей книги, пока же приведем несколько примеров, чтобы показать, на что этот язык похож. Оказывается, для того чтобы начать работать с SQL, не обязательно изучать его формальные правила.
Создадим при помощи SQL новую таблицу в базе данных. В этом примере создается таблица для товаров, предлагаемых на продажу, которые войдут в заказ:
CREATE TABLE item (item_id serial, description char(64) not null, cost_price numeric(7,2), sell_price numeric(7,2));
Здесь мы определили, что таблице необходим идентификатор, который бы действовал как первичный ключ, и что он должен автоматически генерироваться системой управления базой данных. Идентификатор имеет тип serial, а это означает, что каждый раз при добавлении нового элемента item в последовательности будет создан новый, уникальный item_id. Описание (description) - это текстовый атрибут, состоящий из 64 символов. Себестоимость (cost_price) и цена продажи (sell_price) определяются как числа с плавающей точкой, с двумя знаками после запятой.
Теперь используем SQL для заполнения только что созданной таблицы. В этом нет ничего сложного:
INSERT INTO item(description, cost_price, sell_price) values("Fan Small", 9.23, 15.75); INSERT INTO item(description, cost_price, sell_price) values("Fan Large", 13.36, 19.95); INSERT INTO item(description, cost_price, sell_price) values("Toothbrush", 0.75, 1.45);
Основа SQL - это оператор SELECT . Он применяется для создания результирующих множеств - групп записей (или атрибутов записей), которые соответствуют некоторому критерию. Эти критерии могут быть достаточно сложными. Результирующие множества могут использоваться в качестве целевых объектов для изменений, осуществляемых оператором UPDATE , или удалений, выполняемых DELETE .
Вот несколько примеров использования оператора SELECT:
SELECT * FROM customer, orderinfo WHERE orderinfo.customer_id = customer.customer_id GROUP BY customer_id SELECT customer.title, customer.fname, customer.lname, COUNT(orderinfo.orderinfo_id) AS "Number of orders" FROM customer, orderinfo WHERE customer.customer_id = orderinfo.customer_id GROUP BY customer.title, customer.fname, customer.lname
Эти операторы SELECT перечисляют все заказы клиентов в указанном порядке и подсчитывают количество заказов, сделанных каждым клиентом.
Например, база данных PostgreSQL предоставляет несколько способов доступа к данным, в частности можно:
- Использовать консольное приложение для выполнения операторов SQL
- Непосредственно встроить SQL в приложение
- Использовать вызовы функций API (Application Programming Interfaces, интерфейсов прикладного программирования) для подготовки и выполнения операторов SQL, просмотра результирующих множеств и обновления данных из множества различных языков программирования
- Прибегнуть к опосредованному доступу к данным базы PostgreSQL с применением драйвера ODBC (Open Database Connection - открытого интерфейса доступа к базам данных) или JDBC (Java Database Connectivity - интерфейса доступа Java-приложений к базам данных) или стандартной библиотеки, такой как DBI для языка Perl
Системы управления базами данных
СУБД , как уже говорилось ранее, - это набор программ, делающих возможным построение баз данных и их использование. В обязанности СУБД входит:
- Создание базы данных. Некоторые системы управляют одним большим файлом и создают одну или несколько баз данных внутри него, другие могут задействовать несколько файлов операционной системы или же непосредственно реализовывать низкоуровневый доступ к разделам диска. Пользователи и разработчики не должны заботиться о низкоуровневой структуре таких файлов, т. к. весь необходимый доступ обеспечивает СУБД.
- Предоставление средств для выполнения запросов и обновлений. СУБД должна обеспечивать возможность запроса данных, удовлетворяющих некоторому критерию, например возможность выбора всех заказов, сделанных некоторым клиентом, но еще не доставленных. До того как SQL получил широкое распространение в качестве стандартного языка, способы выражения таких запросов менялись от системы к системе.
- Многозадачность. Если с базой данных работают несколько приложений или к ней одновременно осуществляют доступ несколько пользователей, то СУБД должна гарантировать, что обработка запроса каждого пользователя не влияет на работу остальных. То есть пользователям приходится ждать, только если кто-то другой записывает данные именно тогда, когда им нужно прочитать (или записать) данные в какой-то элемент. Одновременно может происходить несколько считываний данных. На поверку оказывается, что разные базы данных поддерживают разные уровни многозадачности и что эти уровни даже могут быть настраиваемыми.
- Ведение журнала. СУБД должна вести журнал всех изменений данных за некоторый период времени. Он может использоваться для отслеживания ошибок, а также (может быть, это даже важнее) для восстановления данных в случае сбоя системы, например внепланового выключения питания. Обычно производится резервное копирование данных и ведется журнал транзакций, т. к. резервная копия может быть полезна для восстановления базы данных в случае повреждения диска.
- Обеспечение безопасности базы данных. СУБД должна обеспечивать контроль над доступом, чтобы только зарегистрированные пользователи могли манипулировать данными, хранящимися в базе, и самой структурой базы данных (атрибутами, таблицами и индексами). Обычно для каждой базы определяется иерархия пользователей, во главе этой структуры стоит «суперпользователь», который может изменять все что угодно, дальше идут пользователи, которые могут добавлять и удалять данные, а в самом низу находятся те, кто имеет право только на чтение. СУБД должна иметь средства, позволяющие добавлять и удалять пользователей, а также указывать, к каким возможностям базы данных они могут получить доступ.
- Поддержание ссылочной целостности. Многие СУБД имеют свойства, способствующие поддержанию ссылочной целостности, то есть корректности данных. Обычно, если запрос или обновление нарушает правила реляционной модели, СУБД выдает сообщение об ошибке.
|
|





